
100次浏览 发布时间:2024-11-14 10:21:55
三大抽样统计分布是指卡方分布(χ2分布),t分布和F分布,是来自正态总体的三个常用的分布。
卡方分布是指符合标准正态分布的样本总体,每个样本的平方和构成的新随机变量称为卡方分布,记为χ2∼χ2(n)。
(1)卡方分布概率密度函数:

(2)卡方分布的期望和方差:E(X)=n,D(X)=2n
(3)概率分布质量函数:
### 卡方分布
def chi_ditribution():
x = np.linspace(0, 10, 100)
fig,ax = plt.subplots(1,1)
linestyles = [':', '--', '-.', '-']
deg_of_freedom = [1, 4, 7, 6]
for df, ls in zip(deg_of_freedom, linestyles):
ax.plot(x, stats.chi2.pdf(x, df), linestyle=ls)
plt.title('卡方分布')
plt.grid(True)
plt.legend()
chi_ditribution()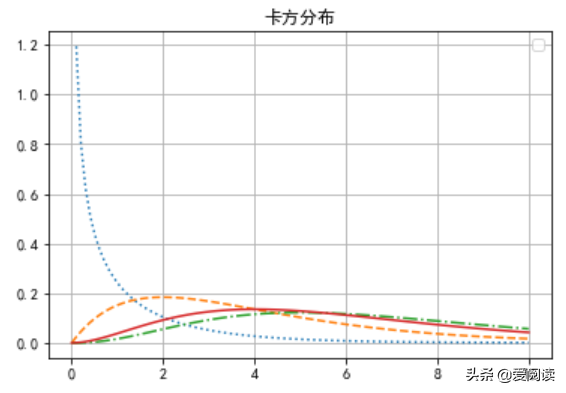
其对应为卡方检验,卡方x2检验可用于拟合性检验和相关性分布,其核心原理在于根据样本数据估计总体频率和期望频率间是否存在限制性差异。
(4)显著性分析应用例子:某咖啡厅通过统计获得如下一组数据,老板想看看不同的职业和咖啡口感间是否存在限制性差异
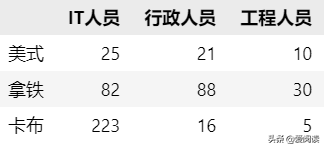
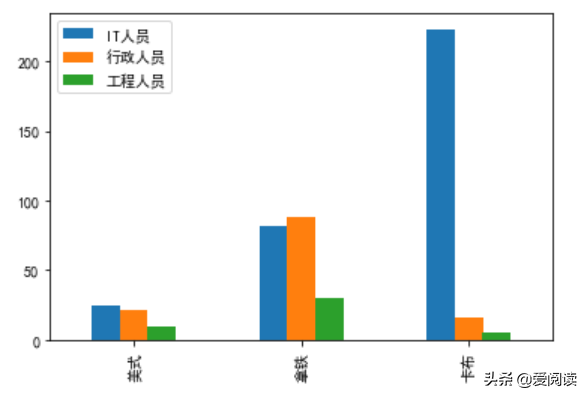
咖啡统计
def cal_chi2(df):
""" 卡方检验 """
kt =chi2_contingency(df)
print('卡方值=%.4f, p值=%.4f, 自由度=%i expected_frep=%s'%kt)
return kt
df.plot(kind='bar')
cal_chi2(df)卡方值=138.2050, p值=0.0000, 可知 不同职业和咖啡口感间不独立,存在显著差异。当然,我们从上面的柱状图也可以明显看出,不同职业对咖啡的口感喜爱是不一样的。
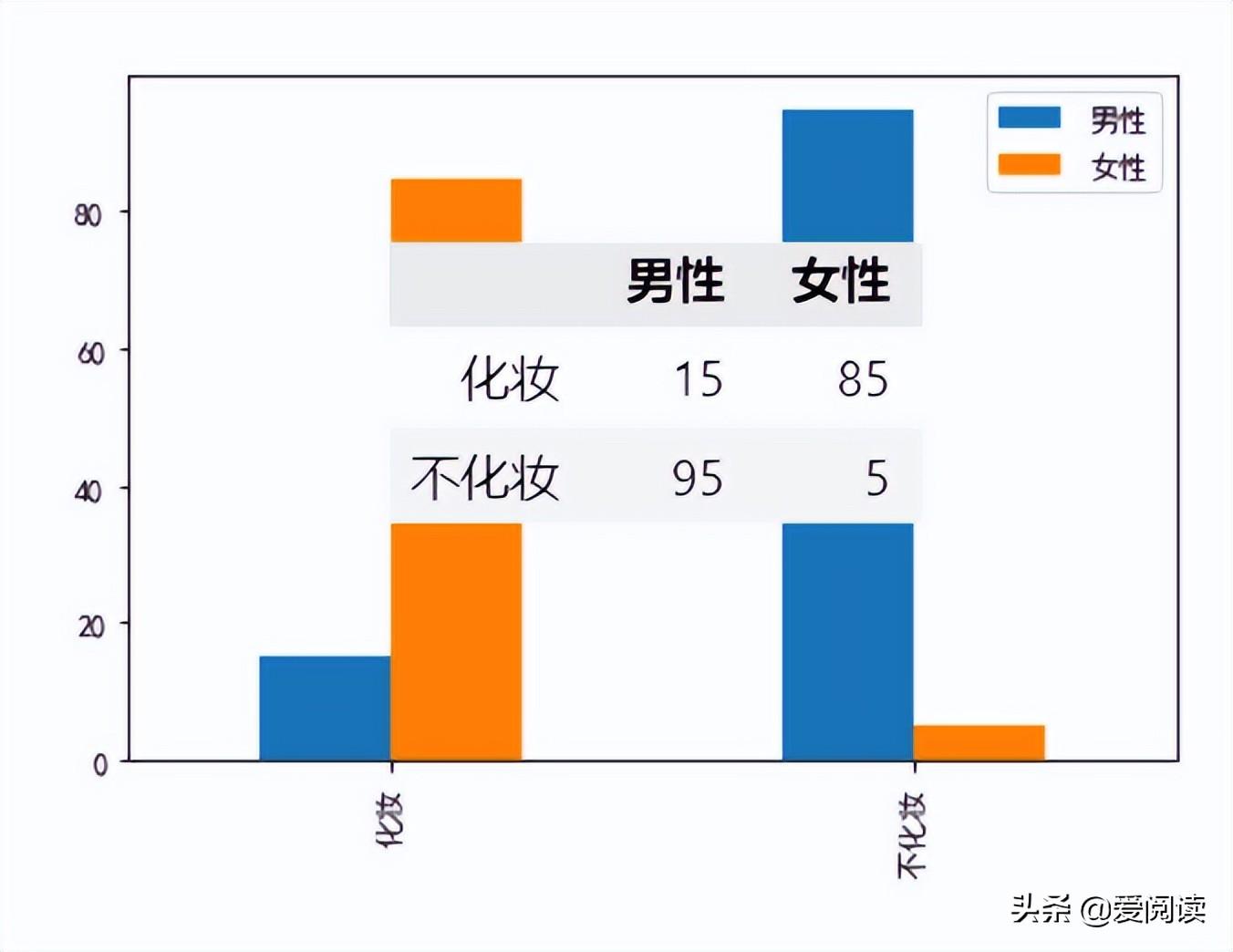
再比如,男性、女性对化妆品的统计数据如下,那么:性别和化妆与否是否存在显著差异?也可以使用卡方检验来解释。
t-分布又称学生氏分布,常用于根据小样本来估计呈正态分布且方差未知的总体的均值。
(1)t-分布概率质量函数:
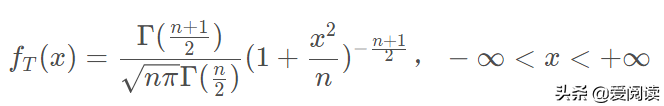
(2) t-分布概率图:
def t_distribution():
""" t-分布 """
x = np.linspace(-5,5,100000)
for i in range(1, 4,1):
y_t = stats.t.pdf(x, i)
plt.plot(x,y_t, label=f"i={i}")
plt.legend()
plt.grid(True)
t_distribution()

针对t分布的检验分为3种:
2.1 单样本t检验:
单样本检测是指用来确定的样本均值和总体总体均值在统计学上是否存在显著差异。
如: 随机抽取某款汽车的进行尾气检测,数据如下,请问此款汽车尾气是否显著大于 20?
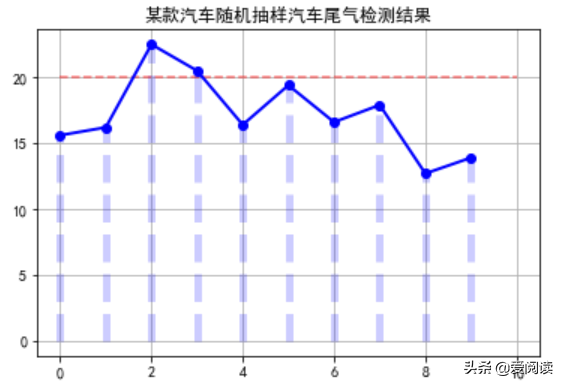
某款汽车随机抽样汽车尾气检测结果

汽车尾气数据分布
很显然是不显著的,t-value=3.001649525885985, p-value=0.014916414248897527。
再比如:已知新生儿平均体重 3.31 kg,从某高寒缺氧区域抽取30例新生儿,平均体重3.21kg, 标准差0.5,请问该地区新生儿体重符合正常标准吗?
我们也可以使用单样本t-检验:p = 0.07079, 我们可以认定根据现有数据信息,不能确定该地区新生儿体重异常。
2.2 配对样本t检验:
配对样本t检验目的是在检验样本差数的均数与0之间的差别的显著性。
比如:某医院研究某款咖啡对成人心肌血流量的研究时,随机抽选12名健康成人进行心肌血流量检测,数据如下,那么,此咖啡对心肌血流量是否有影响? 我们就可以使用配对t-检验进行分析了。

心肌血流量数据
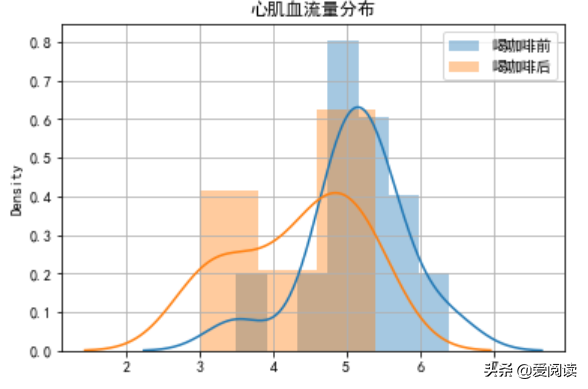
心肌血流量数据直方图
t-检验双尾p-value = 0.0032, 有显著差异。
2.3 独立样本t-检验
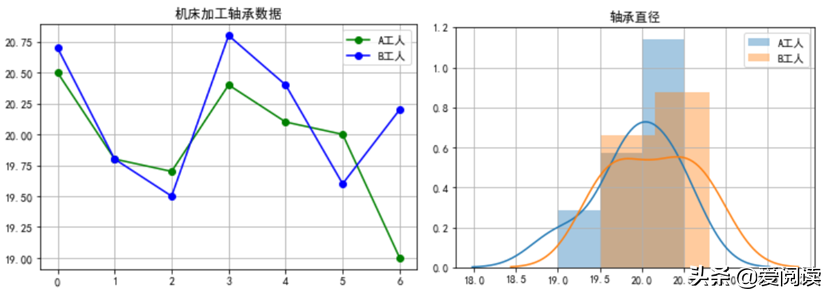
独立样本t-检验目的是判断两个样本均数所对应的总体均数是否有差别。例如,A 和 B工人同一机床上加工轴承零件的直径数据如下,请问A、B加工产品有显著性差异吗?
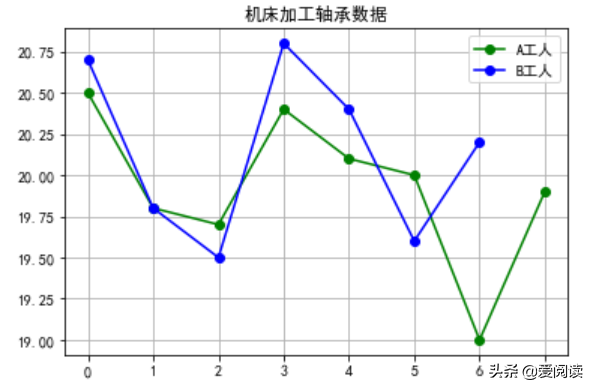
A、B 机床加工轴承数据
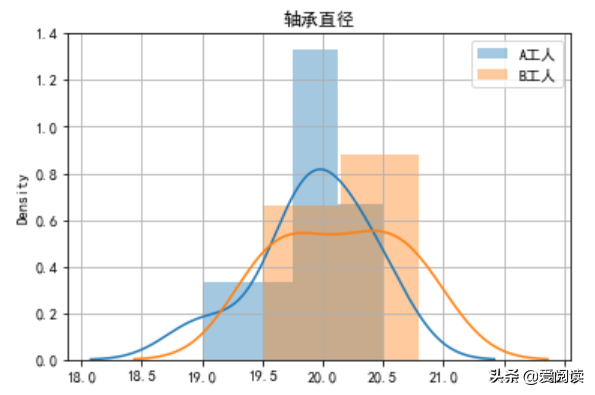
A、B 加工轴承直径分布
独立样本t-检验 p-value=0.4081>0.05, 我们可以认为两人加工精度无显著差异。
F分布是两个服从卡方分布的独立随机变量各除以其自由度后的比值的抽样分布,是一种非对称分布且位置不可互换的分布,对应的F检测也称为方差比率检验、方差齐性检验。
(1)F分布概率函数:
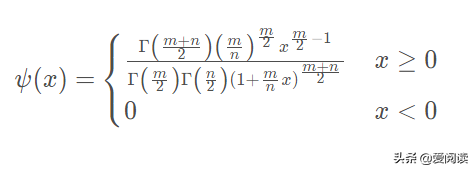
(2)F分布期望和方差:
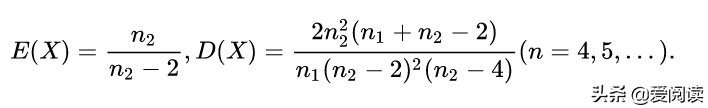
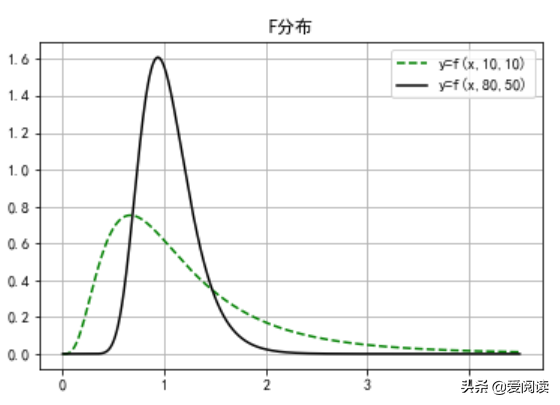
(3)F分布概率分布
#### F分布
def f_distribution():
""" F 分布概率 """
x = np.linspace(0,4.5, 10000)
fd1 = stats.f.pdf(x,10,10)
fd2 = stats.f.pdf(x,80,50)
plt.plot(x, fd1, 'g--',label='y=f(x,10,10)')
plt.plot(x, fd2, 'k-',label='y=f(x,80,50)')
plt.legend()
plt.title("F分布")
plt.grid(True)
f_distribution()
F检验主要是考差两组数据的稳定性,我们还是以上面A工人和B工人加工零件的例子来尝试。
F-检验 p-value = 0.9269, 说明两组数据稳定性无显著性差异,反应了A工人和B工人加工零件的稳定性相当。
相关文章
